The K-Nearest Neighbors algorithm, one of the "Top Ten Machine Learning Algorithms", is a classification and regression algorithm that is simple and easy to understand. Today, let's learn the basic principles of the KNN algorithm and implement it in Python. Finally, we will illustrate its application value through a case study.
Intuitive understanding of KNN algorithm
(Add an intuitive picture)
It is based on the simple assumption that points that are close together are more likely to belong to the same category. In the big proverb, it is "smelly taste", or "near Zhu is red, near ink is black."
It does not attempt to establish a predictive model for display, but rather determines the category to which it belongs by directly advancing the training points of the predicted points.
The implementation of the K-nearest neighbor algorithm is mainly based on three basic elements:
K's choice;
Determination of the distance measurement method;
Classification decision rules.
Below, around the three basic elements, explore its classification implementation principles.
The principle of KNN algorithm
Algorithm step
The implementation steps of the K-nearest neighbor algorithm are as follows:
According to the given distance metric, find the kk points nearest to xx in the training set TT, and the neighborhood of xx covering the kk points is denoted as Nk(x)Nk(x);
In Nk(x)Nk(x), the category yy of the sample is determined according to the classification decision rule:
y=arg maxcj∑xi∈Nk(x)I(yi=cj),i=1,2,⋯,N;j=1,2,⋯,Ky=arg maxcj∑xi∈Nk(x)I(yi =cj),i=1,2,⋯,N;j=1,2,⋯,K.
K's choice
The K-nearest neighbor algorithm is very sensitive to the choice of K. The smaller the K value, the higher the complexity of the model, which tends to produce over-fitting; the larger the K value, the easier the overall model becomes, and the approximate approximation error of learning increases.
In practical applications, a relatively small K value is generally used. A cross-validation method is used to select an optimal K value.
Distance metric
Distance metrics generally use Euclidean distance. It is also possible to use an LpLp distance or a Ming distance as needed.
Classification decision rule
The classification decision in the K-nearest neighbor algorithm is mostly carried out by the majority vote method. It is equivalent to minimizing the risk of seeking experience.
But there is a potential problem with this rule: it is possible that the number of votes in multiple categories is the highest. At this time, which category should I judge?
There are several ways to solve this problem:
Select one randomly from the highest category with the same number of votes;
Further weighting the number of votes by distance;
Reduce the number of Ks until you find a unique maximum number of votes.
Advantages and disadvantages of the KNN algorithm
advantage
High precision
Insensitive to outliers
No assumptions about the distribution of the data
Disadvantage
High computational complexity
In the case of high dimensionality, you will encounter the problem of "dimensional curse"
Algorithm Implementation of KNN Algorithm
Import os os.chdir('D:\\my_python_workfile\\Project\\Writting')os.getcwd()'D:\\my_python_workfile\\Project\\Writting'from __future__ import divisionfrom collections import Counter#from linear_algebra import distance #from statistics import meanimport math, randomimport matplotlib.pyplot as plt# Define the voting function defraw_majority_vote(labels): votes = Counter(labels) winner,_ = votes.most_common(1)[0] return winner
There is a potential problem with the above voting function: it is possible that the number of votes in multiple categories is the highest.
The following function implements the third classification decision method in the solution.
# defmajority_vote(labels): """assumes that labels are ordered from nearest to farthest """ vote_counts = Counter(labels) winner,winner_count = vote_counts.most_common(1)[0] num_winners = len([count for count in vote_counts .values() if count == winner_count]) if num_winners == 1: return winner else: return majority_vote(labels[:-1]) # try again wthout the farthest# define distance functionimport math#### subtraction definition defvector_substract( v,w): """substracts coresponding elements""" return [v_i - w_i for v_i,w_i in zip(v,w)]defsquared_distance(v,w): """""" return sum_of_squares(vector_substract(v , w))defdistance(v,w): return math.sqrt(squared_distance(v,w))######################################### ################ define sum_of_squares### The point multiplication of the vector defdot(v,w): return sum(v_i * w_i for v_i,w_i in zip(v,w)) ### Vector bungalow and defsum_of_squares(v): """v_1*v_1+v_2*v_2+...+v_n*v_n""" return dot(v,v)# classifierdefknn_classify(k,labeled_points,new_point): " ""each labeled point should be a pair (point,l Abel)""" #order the labeled points from nearest to farthest by_distance = sorted(labeled_points, key = lambda (point,_):distance(point,new_point)) # find the labels for the k cloest k_nearest_labels = [label for _ ,label in by_distance[:k]] # and let them vote return majority_vote(k_nearest_labels) Application of KNN algorithm: case study # cities = [(-86.75,33.5666666666667,'Python'), (-88.25,30.6833333333333, 'Python' ), (-112.016666666667, 33.4333333333333, 'Java'), (-110.933333333333, 32.1166666666667, 'Java'), (-92.2333333333333, 34.7333333333333, 'R'), (-121.95, 37.7, 'R'), (-118.15, 33.8166666666667, 'Python'), (-118.233333333333, 34.05, 'Java'), (-122.316666666667, 37.8166666666667, 'R'), (-117.6, 34.05, 'Python'), (-116.533333333333, 33.8166666666667, 'Python') , (-121.5, 38.5166666666667, 'R'), (-117.166666666667, 32.7333333333333, 'R'), (-122.383333333333, 37.6166666666667, 'R'), (-121.933333333333,37.3666666666667, 'R'), (-122.016666666667, 36.9833333333333 , 'Python'), (-104.716666666667, 38.8166666666667, 'Python'), (-104. 866666666667, 39.75, 'Python'), (-72.65, 41.7333333333333, 'R'), (-75.6, 39.6666666666667, 'Python'), (-77.0333333333333, 38.85, 'Python'), (-80.2666666666667, 25.8, 'Java '), (-81.3833333333333, 28.55, 'Java'), (-82.5333333333333, 27.9666666666667, 'Java'), (-84.4333333333333, 33.65, 'Python'), (-116.216666666667, 43.5666666666667, 'Python'), (-87.75 , 41.7833333333333, 'Java'), (-86.2833333333333, 39.7333333333333, 'Java'), (-93.65, 41.5333333333333, 'Java'), (-97.4166666666667, 37.65, 'Java'), (-85.7333333333333, 38.1833333333333, 'Python' ), (-90.25, 29.9833333333333, 'Java'), (-70.3166666666667, 43.65, 'R'), (-76.6666666666667, 39.1833333333333, 'R'), (-71.0333333333333, 42.3666666666667, 'R'), (-72.5333333333333, 42.2, 'R'), (-83.0166666666667, 42.4166666666667, 'Python'), (-84.6, 42.7833333333333, 'Python'), (-93.2166666666667, 44.8833333333333, 'Python'), (-90.0833333333333, 32.3166666666667, 'Java') , (-94.5833333333333,39.1166666666667, 'Java'), (-90.3833333333333, 38.75, 'Python'), (-108.533333333333, 45.8, 'Python'), (-115.166666666667, 36.08333 33333333, 'Java'), (-71.4333333333333, 42.9333333333333, 'R'), (-74.1666666666667, 40.7, 'R'), (-106.616666666667, 35.05, 'Python'), (-78.7333333333333, 42.9333333333333, 'R') , (-73.9666666666667, 40.7833333333333, 'R'), (-80.9333333333333, 35.2166666666667, 'Python'), (-78.7833333333333, 35.8666666666667, 'Python'), (-100.75, 46.7666666666667, 'Java'), (-84.5166666666667, 39.15 , 'Java'), (-81.85, 41.4, 'Java'), (-82.8833333333333, 40, 'Java'), (-97.6, 35.4, 'Python'), (-122.666666666667, 45.5333333333333, 'Python'), (-75.25,39.8833333333333, 'Python'), (-80.2166666666667, 40.5, 'Python'), (-71.4333333333333, 41.7333333333333, 'R'), (-81.1166666666667, 33.95, 'R'), (-96.7333333333333, 43.5666666666667, 'Python'), (-90, 35.05, 'R'), (-86.6833333333333, 36.1166666666667, 'R'), (-97.7, 30.3, 'Python'), (-96.85, 32.85, 'Java'), ( -98.4666666666667, 29.5333333333333, 'Java'), (-111.966666666667, 40.7666666666667, 'Python'), (-73.15, 44.4666666666667, 'R'), (-77.3333333333333, 37.5, 'Python'), (-122.3, 47.5333333333333, ' Python'), (-95.9, 41.3, 'Python'), (-95.35, 29.9 666666666667, 'Java'), (-89.3333333333333, 43.1333333333333, 'R'), (-104.816666666667, 41.15, 'Java')] cities = [([longitude,latitude],language) for longitude,latitude,language in cities] # plot_state_bordersimport resegments = []points = []lat_long_regex = r"
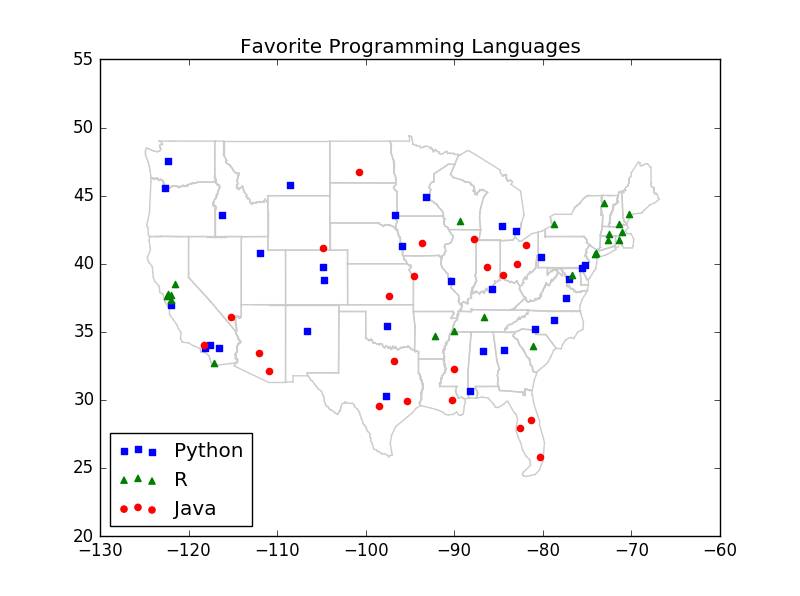
#try several different values ​​for kfor k in [1,3,5,7]: num_correct = 0 for city in cities: location,actual_language = city other_cities = [other_city for other_city in cities if other_city != city] predicted_language = knn_classify( k,other_cities,location) if predicted_language == actual_language: num_correct += 1 print k,"neighbor[s]:",num_correct,"correct out of ",len(cities)1 neighbor[s]: 40 correct out of 753 Neighbor[s]: 44 correct out of 755 neighbor[s]: 41 correct out of 757 neighbor[s]: 35 correct out of 75
Projector Lamp,Projector Light Bulb,Projector Lamp Replacement,Projector Bulb Replacement
Shenzhen Happybate Trading Co.,LTD , https://www.szhappybateprojectors.com